Bienvenue sur ScienQuest
ScienQuest un logiciel en ligne permettant de consulter des corpus textuels structurés et annotés, d'y rechercher des mots, séquences de mots, ou arbres syntaxiques, et d'afficher les résultats sous forme de condordances et de fréquences.Recherche en 5 étapes
ScienQuest permet d'effectuer des recherches dans les corpus en 5 étapes:
1. Onglet Corpus: sélection du corpusScienQuest contient plusieurs corpus en plusieurs langues, qui ne sont pas tous annotés de la même manière. Les annotations sont généralement en parties du discours, lemmes et dépendances syntaxiques, mais les conventions de découpage en tokens, les jeux d'étiquettes et les modèles syntaxiques peuvent varier. |
|
|
| ↓ | ||
2. Onglet Textes: sélection d'un sous-corpusÀ cette étape, on peut choisir un sous-corpus en fonction des méta-données disponibles pour ce corpus, ou bien texte par texte. Mais on peut aussi garder tout le corpus ! |
|
|
| ↓ | ||
3. Onglet Recherche: recherche dans la sélectionL'asssitant permet de rechercher des mots, séquences de mots, ou patterns syntaxiques dans le sous-corpus sélectionné à l'étape précédente.Les listes de mots et les regex sont supportées (passez la souris sur le symbole |
|
|
| ↓ | ||
4. Onglet Résultats: concordancesLes résultats de la recherche peuvent être consultés en mode concordances KWIC et téléchargés au format CSV. |
|
→
|
| ↓ | ||
5. Onglet Résultats/Statistiques: statistiquesLes résultats de la recherche peuvent aussi être consultés sous forme de statistiques: fréquences relatives et absolues en fonction des métadonnées présentes dans le corpus. Les statistiques peuvent être téléchargées au format CSV. |
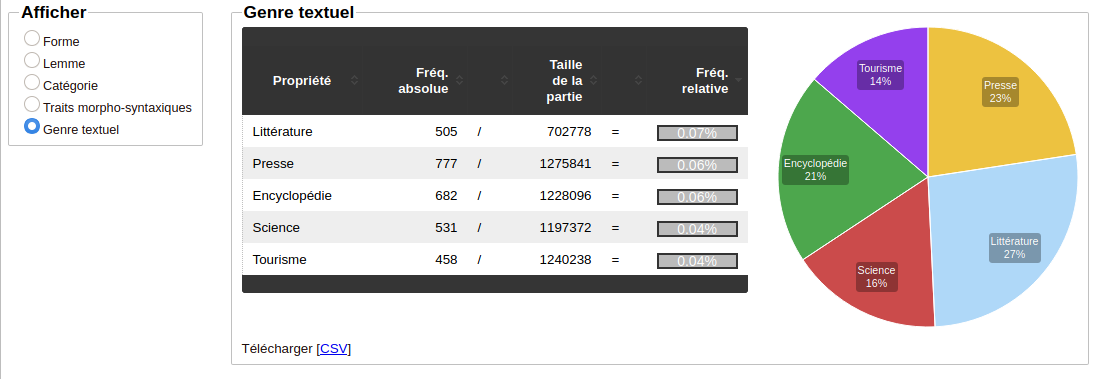
|
→
|